

The following post goes over and outlines a few methods for training a blind locomotion policy for a quadruped robot, most of the work shown here has been done during my time at the CNRS-AIST JRL (Joint Robotics Laboratory), IRL, Japan for my undergraduate thesis under the supervision of Dr. Mitsuharu Morisawa with support from Rohan Singh.
Note: Detailed results and video clips can be found in the Results section below.
The following GitHub Repo can be used to replicate the results from the videos show in this blog post.

This work is a continuation of my previous post that can be found here.
Let’s establish a few priors and baselines so that we can gradually build on top of them to achieve what can be considered a robust proprioceptive baseline.
Base Policy
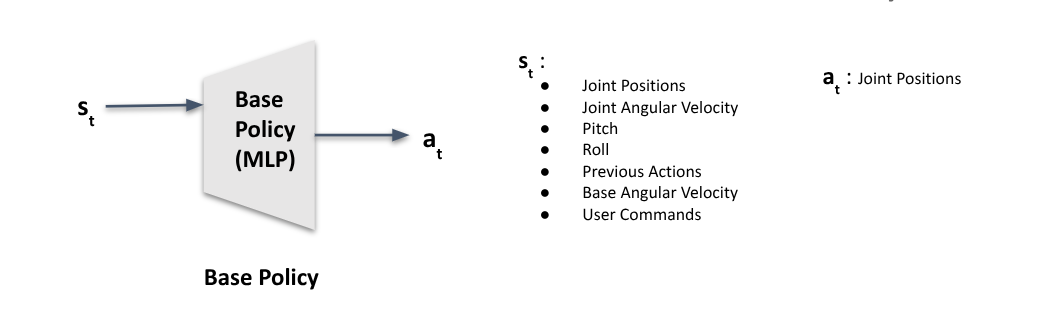
The simplest policy can be designed by passing the current state of the robot $S_t$ — which consists of joint velocities, joint positions, roll, pitch, base angular velocity, and user commands — along with the actions from the previous timestep $a_{t-1}$, into a Multi-Layer Perceptron (MLP) network. The MLP outputs actions that are then used to compute the joint angles.
Base Policy with Observation History
While the base policy with only the previous timestep’s actions is a good starting point, it works well only when the quadruped is walking on a flat surface. Introducing even the smallest obstacles can cause the robot to stumble and fall. This shouldn’t come as a surprise since the policy has no awareness of what occurred outside the current timestep. Reacting to external disturbances based solely on a single timestep is difficult, so the next logical upgrade is to provide the policy with a history of past states to improve its ability to handle disturbances.
This can be achieved in various ways. For example, the MLP can be replaced with an RNN-based approach like LSTM or GRU. However, since we are building things from the ground up, we’ll use a simpler method: concatenating the previous 4 states with the current state to create a total of 5 states within a sliding window.
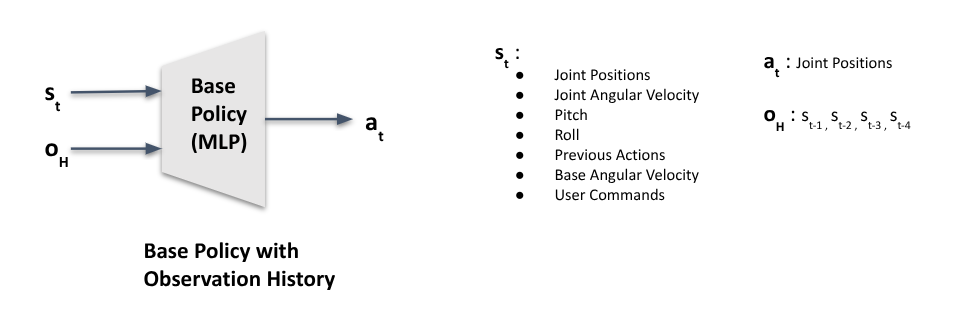
For this particular use case, I found empirically that performance improves as the state window increases from 0 to 4. Beyond this, the gains become insignificant, so I limited the window to 4 past states. Your mileage may vary, so feel free to experiment with the window size. If you want to consider much longer horizons, such as 50 or 100 past states, running these states through a 1D CNN layer before feeding them into the base policy can help avoid creating an excessively large input layer.
Effects of Observation History
At this point, you might be curious (and perhaps a little impatient) to test whether adding just 4 past states actually makes a difference. Here’s a plot illustrating the impact of observation history:
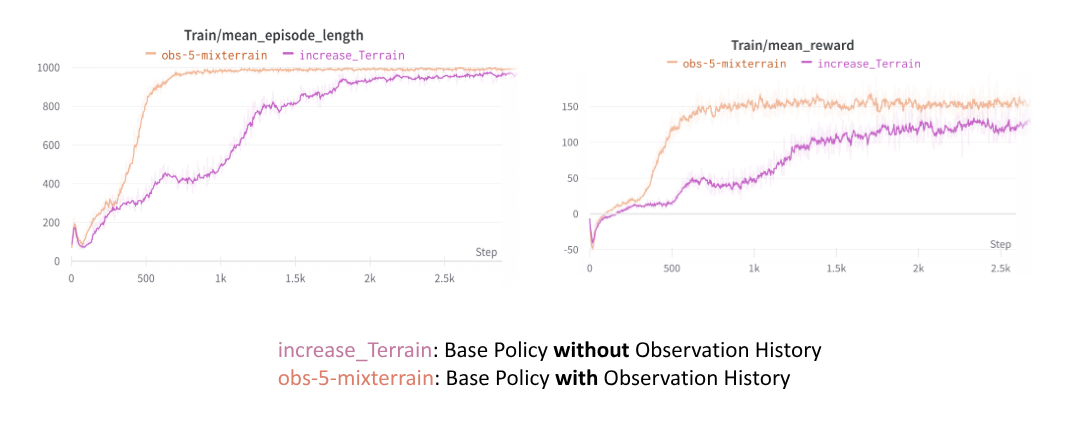
Leaving aside the cringe-worthy names in the plot legend and using the labels at the bottom, it’s clear that the agent reaches the full episode length (i.e., the agent doesn’t “die”) much sooner when provided with observation history. Additionally, the reward collected by the agent is higher when observation history is included.
It’s important to note that while the difference between the two architectures appears to narrow as the number of steps increases, their performances do not completely merge or match. (evident from the steady state difference in their rewards)
To give a more concrete idea of how all this actually performs on a real robot, here is a quick test of the Base Policy with Observation History compared against the default MPC controller for the Unitree Go1 Robot.
Note that the default controller experiment had to be cut short due to the fact that the constant trotting by the MPC was causing the robot to swerve to the sides and would have likely resulted in a fall if the experiment continued.
Here is another quick outdoor run using the default MPC controller and the Base Policy with Observation History.
Do note that the default MPC controller couldn’t even go over the initial ledge. While the RL controller was able to do it somtimes, you can clearly see the shotcomings of both the controllers. Now lets take a look at the next possible upgrade to improve our RL controller.
Privileged Information
Privileged Information refers to the set of observations that are typically not available in the real world but can easily be obtained inside a physics engine/simulation. Some of this information might be relavent and can improve the performance of the base policy significantly if provided.
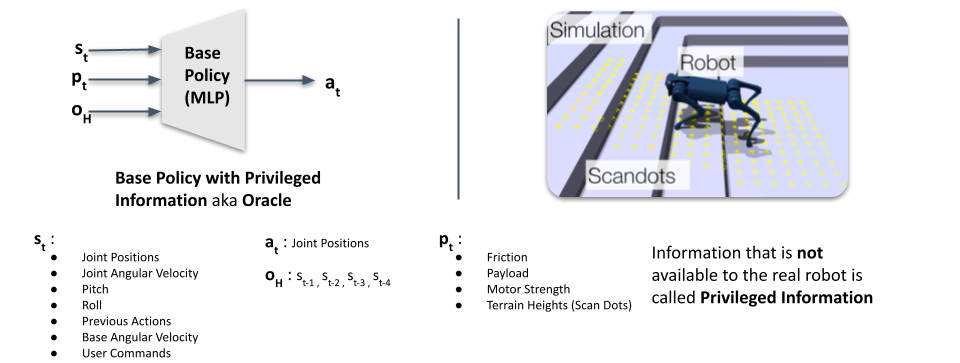
For example, it might be of use to give the friction cofficient of the surface the robot is currently walking on as an input to the policy but in real life its hard to retrofit the robot with sensors to measure the friction.
A small note on the nomeclature, a policy that is directly fed in priviliged information is typically refered to as an oracle since it symbolizes the best case performance a policy can achieve in an ideal sitatuion where any information needed can be supplied, in some cases such an oracle is also refered to as a teacher since its used to teach other policies. TLDR: Base Policy with Privileiged information is sometimes also called as a teacher or an oracle.
At this point you might be wondering what is the point of discussing about such information that is not easy to read or measure in the real world since our final goal is to deploy policies on a real robot. Well reader, while its not easy to measure these parameters in the real world it doesn’t stop us from indirectly infereing these values by other means.
For example even in humans, while we cannot in many cases look at the surface and guess the friction we can definetly get a feel of the friction the movement we start walking over it, this could be due to the difference in effort required to move our leg or the rate at which our leg moves for a given effort and so on… therefore we can indirectly feel the friction via our senses.
Similarly, in this case we are interested in certain priviliged information metrics that while cannot be directly measured can be indirectly infered via other indirect metrics such as joint torques, joint velocities and so on via proprioception.
Effects of Privileged Information
Before we dive into all the different ways in which privileged information can be indirectly obtained and infered, lets take a look at the ideal case where we have all the priviledged information we want and compare such a policies performance with the base policy that uses only observation history and a base policy without observation history.
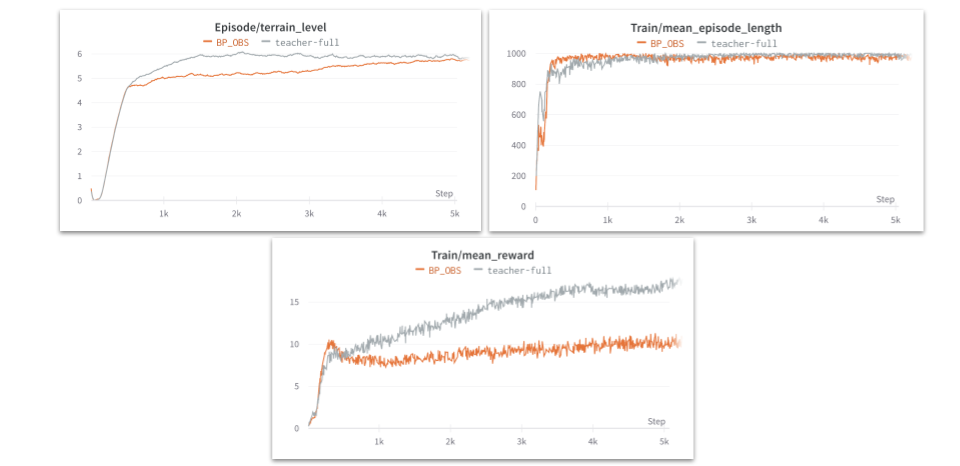 Let’s try to spend some time to understand the plots in the above image, the orange line represents the base policy with only observation history whereas the gray plot represents the base policy with priviliged information and observation history.
Let’s try to spend some time to understand the plots in the above image, the orange line represents the base policy with only observation history whereas the gray plot represents the base policy with priviliged information and observation history.
As you can notice from the plot on terrain level, the priviliged information policy reaches terrains with higher difficulty level faster when compared to the policy that just uses observation history. The plot of mean reward is a clear indicator that while both the policies might reach the max episode length, the priviliged information based policy clearly scores a higher reward when comapred to the policy with only observation history.
Another interesting point to keep in mind is that the episode length plot has some intial ups and downs where at one point the policy with only observation history seems to be surviving for longer when compared to the policy with privileged information and if this seems counter intutive, keep in mind that the policy with the privilieged information is also progressing towards much more difficult terrain as can be infered from the terrain level plot and this could result in its episode length going slightly lower.
Transfer Learning Methods to use Priviliged Information
Let us now shift our focus towards how we can infer priviliged information indirectly so that they can be used during real world deployments. If implemented properly we are looking for a performance that is better than the base policy with just observation history but is lower than the performance of the oracle/teacher. (Take a look at the reward plot from the picture above - we want to basically introduce a new method that will lie between the lines)
Almost all the methods that try to infer privileged information try to derive this either explicitly or implicitly from the observation history. And likewise most methods that have a training component in simulation try to build an oracle/teacher and use a transfer learning/knowledge distillation framework.
Teacher - Student Architecture
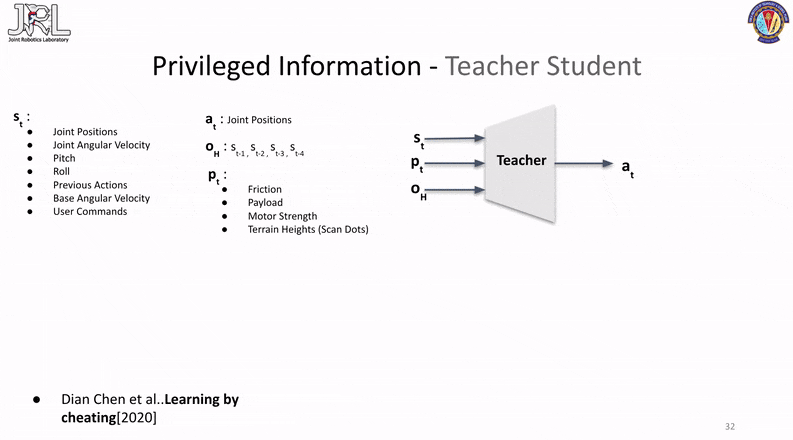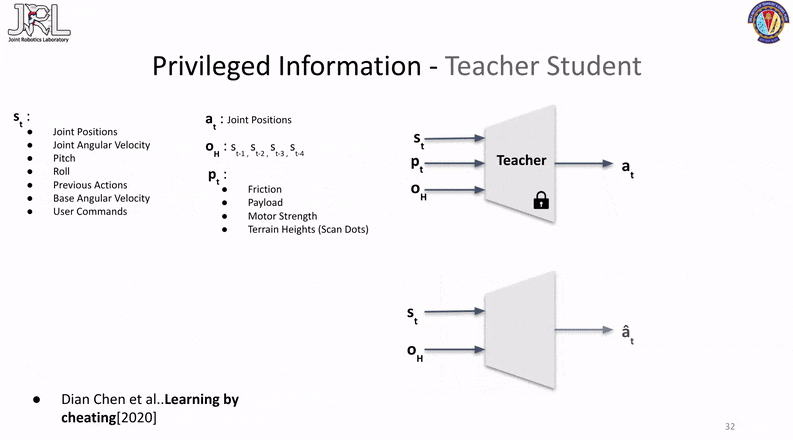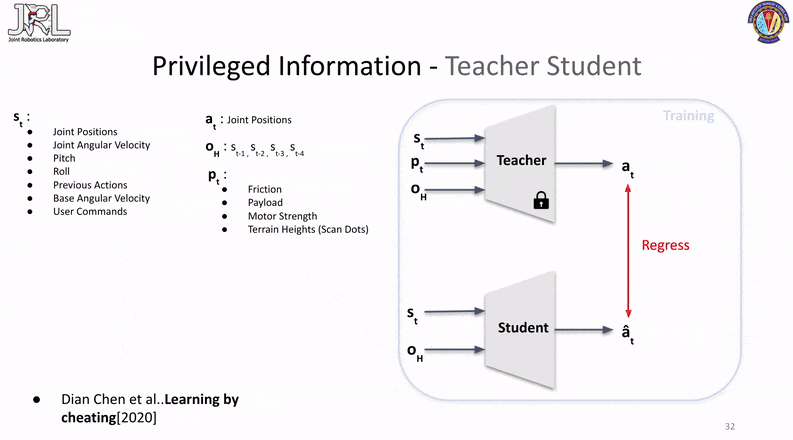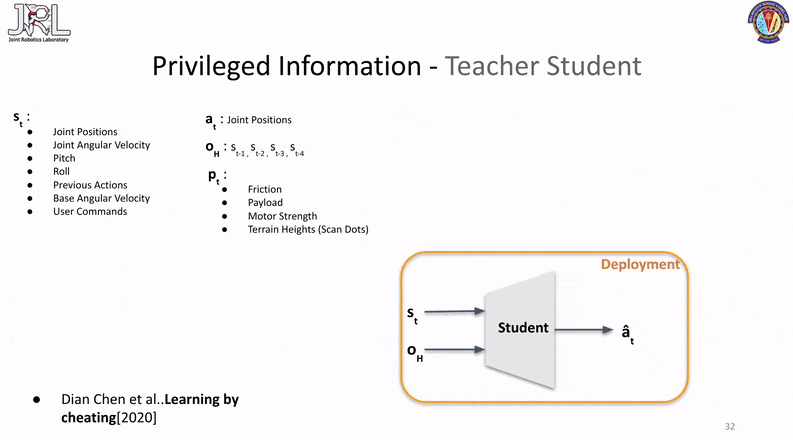
Note that while the network architeture is based on the original paper, the observations being passed have been tailored to our current use case.
The first method we will take a look at is originally from a paper called learning by cheating, and is quite commonly referred to as the teacher-student transfer learning framework.
This method consists of two-phases, the first phase involves the training of an oracle/teacher (typically done in simulation) with all the ground truth/privileged information given to the base policy as part of its observations.
The second phase consists of freezing the trained teacher policy and training a seperate student network to mimic the outputs of the teacher network through regression without the privilieged information being passed in as observations.
The important distinction to note here is the fact that the teacher and the student are two different networks with different sizes and the teacher cannot be copied or reused as a warmstarter for the student since the number of inputs for both (aka. their observations) are different.
Rapid Motor Adaptation

Note that while the network architeture is based on the original paper, the observations being passed have been tailored to our current use case.
The second method we are going to take a look at tries to take a slightly different approach to essential obtain the same results(infer priviliged information) but with a few advantages and perks.
This approach is from a paper titled “Rapid Motor Adaptation” where they essentially propose an architeture that will enable us to reuse the bases policy or the teacher network in the second phase of the training instead of starting with a fresh student network with random weights.
This is accomplished by passing the priviliged information as latent information instead of their raw values during phase one of the training with the help of an encoder called the priviliged information encoder in the figure.
During phase two training, a new network called the observation history encoder is trained to mimic the output of the privliged information encoder despite only being passed the observation history and the output of this network is used to replace the latent information that was being sent during phase one by the privilged information encoder. This enables us to reuse the teacher/base policy from phase one in phase two as well.
One advantage of this method is the fact that since the privileged information is being compressed into a latent vector, more amount of privilieged information can be input to the encoders without the need for increasing the size of the network/input layers when compared to passing this data as raw values.
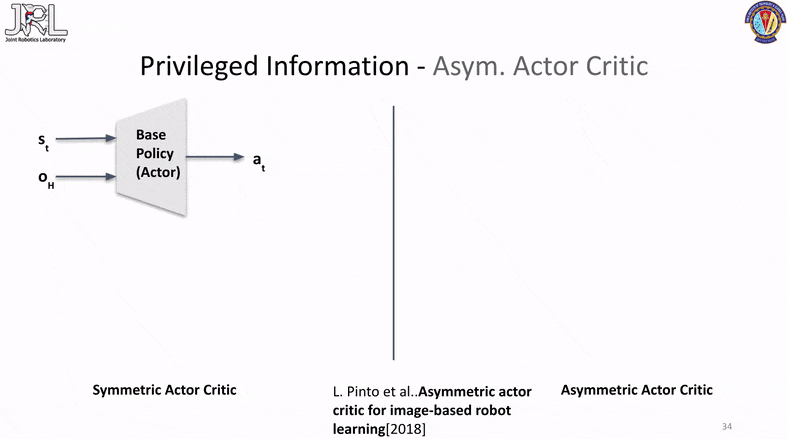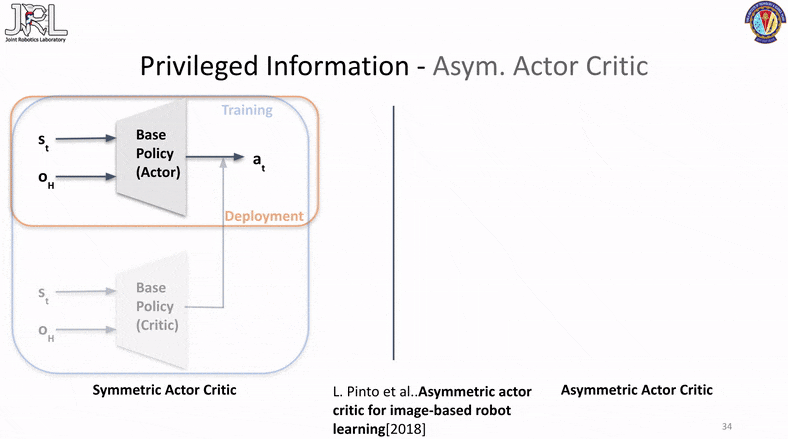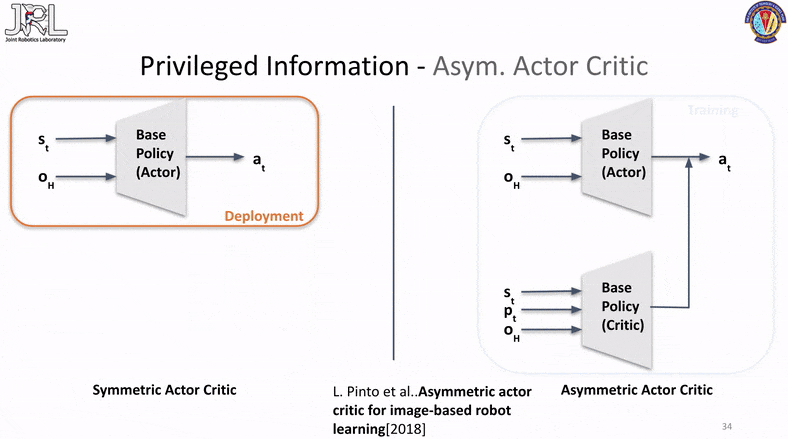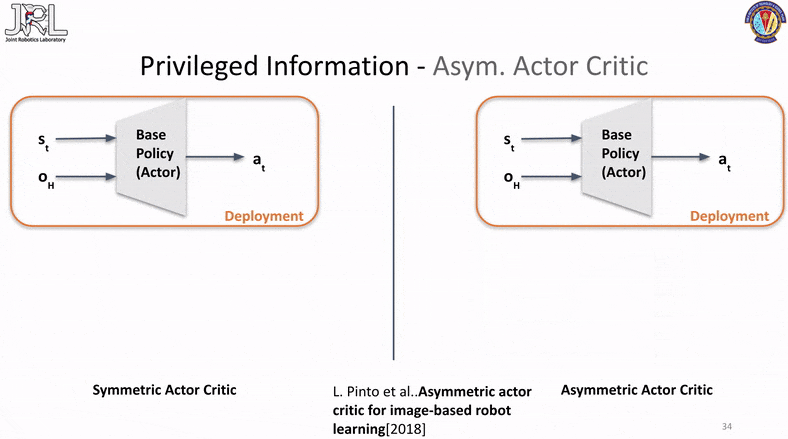
Asym. Actor Critic
Our final method is called Asymmetrical Actor Critic that was originally published in “Asymmetric actor critic for image-based robot learning”. This method has several advantages and one of the most significant one is the fact that it has only a single phase of training involved.
This is accomplished by passing the privilged information either in a latent state via an encoder or directly as raw inputs to the critic network, the idea behind this is the fact that the critic is used to compute the value function for state/action transitions and the more information the critic has the better it can assign value functions and therefore the better a critic can judge or help guide the actor, the better the actor performs and learns. While this method might seem like a solid replacement for the above two and a clear winner, it has a few pratical issues and perks that one should be aware of, one of them is the fact that this is a very indirect method of latent information transfer with no visibilty of the transfer to inspect or verify. Another is the fact that asym. actor-critic arch is prone to instability in certain scenarios which can lead to sudden collapses in the loss and/or value functions.
Results
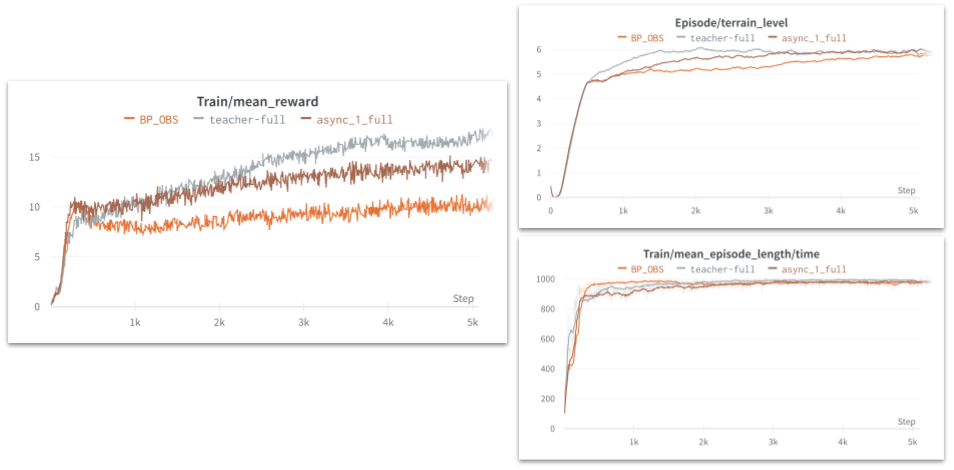
In the final figure you can see that we have accomplished our objecteing sive of finding a method that would perform better than the observation history base line and be below the therotical limit of performace possible (i.e the oracle).
Here is a video compilation of the above policy architeture trained and deployed on a Unitree Go1. If you wish to try out the pre-trained policy on your own Go1 robot, please refer to the GitHub Repo associated with this post.
While the training code for this paticular implementation cannot be shared at this point in time, the deployment code is a good starting point to understand the observations and the network arch being used, this combined with other resouces linked below will get you started training your own policy in no time. Furthermore, I will also provide links and discuss in more detail about sim2real for first time deplyoments and some more tips and tricks to get a policy sucessfully transfered from sim to your robot.
Here is a video version of the above post as part of my JRL Seminar Talks